







 Myths Busted! What They Don’t Tell You!")


Bringing Virtual Faces to Life with AI Magic
In the fascinating world of artificial intelligence, where algorithms and data dance together, a remarkable creation has emerged: VASA-1. This cutting-edge AI model, developed by Microsoft Research, has the power to transform a static portrait photo into a dynamic talking face video. Imagine this: you have a cherished photo of your grandpa telling a story, but the moment is frozen in time. What if you could bring that picture to life, with grandpa’s face moving and his voice filling the air? That’s the magic of VASA-1, a mind-blowing AI model created by Microsoft.
What Is VASA-1?
VASA-1 stands for Visual Affective Skill Augmentation, and it’s like a digital sorcerer that weaves magic with pixels and sound waves. Here’s how it works: You provide VASA-1 with a single portrait photo and an accompanying speech audio clip. The AI then combines these elements to create a lifelike talking face video. It’s like giving a voice to a silent picture, turning it into a living, breathing character.
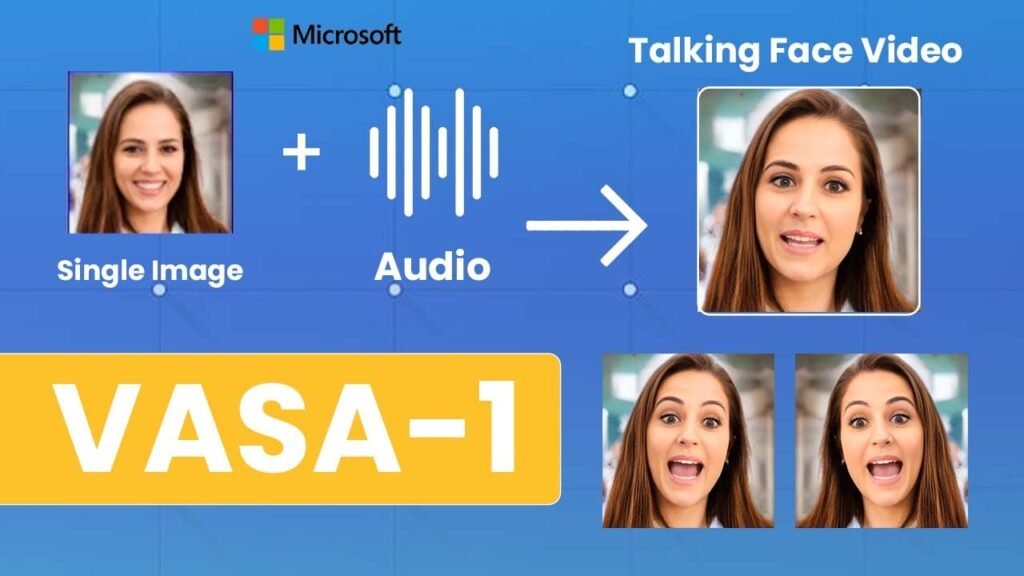
The Art of Realism
VASA-1 doesn’t settle for mediocrity. It’s not content with mere lip movements; it aims for authenticity and liveliness. Here’s what it brings to the table:
- Precise Lip-Audio Sync: VASA-1 ensures that the lips move in perfect harmony with the spoken words. No awkward delays or mistimed cues here!
- Facial Nuances: Ever notice how a raised eyebrow or a subtle smile adds depth to a conversation? VASA-1 captures these nuances, making the talking face feel more human.
- Natural Head Movements: A nod, a tilt, or a thoughtful glance—these small head motions contribute to the overall realism. VASA-1 masters them effortlessly.
Behind the Scenes
The secret sauce lies in VASA-1’s core innovations:
- Holistic Facial Dynamics: VASA-1 operates in a face latent space, where it crafts facial dynamics and head movements. Think of it as a choreographer for virtual faces.
- Expressive and Disentangled Latent Space: This fancy term refers to the AI’s ability to separate different facial features. It’s like untangling a complex knot, allowing VASA-1 to create diverse expressions.
- Video Generation Speed: VASA-1 doesn’t keep you waiting. It churns out 512×512 videos at up to 40 frames per second. That’s real-time magic!

Responsible AI
Before you imagine VASA-1 impersonating real people, hold your horses. All those portrait images on the VASA-1 page? They’re virtual, non-existing identities generated by other AI models. VASA-1 focuses on visual affective skills for interactive characters, not mimicry. No product or API release plans—just pure research wonder.
Benefits of Microsoft VASA-1
VASA-1, the enchanting creation from Microsoft Research, isn’t your run-of-the-mill AI model. It’s like a digital alchemist, weaving lifelike talking faces from mere static images and speech clips. Let’s unravel the magical benefits of VASA-1:
- Hyper-Realistic Talking Faces: VASA-1 goes beyond lip-syncing; it crafts talking faces that feel alive. Imagine a portrait photo suddenly speaking, lips moving in sync with audio—like a scene from a wizard’s tale.
- Facial Nuances and Emotions: VASA-1 captures subtleties—the raised eyebrow, the half-smile, the thoughtful glance. It’s not just about words; it’s about emotions. These nuances make the generated faces believable and relatable.
- Natural Head Movements: A nod, a tilt, a turn—VASA-1 adds these natural head motions. It’s as if the character is truly engaged in conversation, reacting to every word.

- Controllable Generation: Users hold the reins. Specify gaze direction, perceived distance, even emotional state. Want your talking face to look intrigued or amused? VASA-1 obeys.
- Real-Time Efficiency: VASA-1 doesn’t keep you waiting. It generates 512×512 video frames at 45fps in offline mode and up to 40fps in online streaming mode. Lightning-fast magic!
- Educational Equity and Accessibility: Imagine avatars aiding education, bridging communication gaps for those with challenges. VASA-1 offers companionship, therapeutic support, and more.
The Future of Conversations
Imagine avatars in virtual meetings, mimicking human conversational behaviors. VASA-1 paves the way for this future. So next time you see a talking face video, remember the AI wizardry behind it—a single photo, a speech clip, and VASA-1 conjuring lifelike magic.
In a world where pixels meet emotions, VASA-1 whispers, “Watch me turn stillness into symphony.” So, the next time you look at a cherished photo, remember – it might not be as static as you think. With VASA-1 on the horizon, the future of storytelling is looking pretty darn lively.



YouJizz Highly informative articles and reviews right now